Tect by: Chaudhary Muhammad Aqdus Ilyas, Department of Computer Science & Technology, University of Cambridge
Nowadays, we are having faster GPUs but there is an urgent need to optimise the whole process of training large deep learning models that are not only computationally expensive, but also a source of increasing carbon footprint. We are aware that GPUs are optimised for training large AI models and they can process multiple computations simultaneously. They have a larger number of cores, which allows for better computation of multiple parallel processes. However, we are still facing certain challenges, particularly DRAM limitation of GPUs.
First thing to understand and calculate how much GPU memory you need for training without actually running it. This can be calculated by identifying the size of your model and size of your batches. For instance, AlexNet uses 1.1GB of global memory to train with a batch size of 128 layers, which is merely 5 convolutional layers + 2 fully-connected layers. In the case of a larger model, such as the VGG-16, a batch size of 128 will require around 14GB of global memory. In case, if we wish to train a model that is larger than VGG-16, we may have a few alternatives for overcoming the memory constraint.
- Reducing Batch size: This could slow down the training process and impact on accuracy of the model
- Multiple GPUs: Splitting up your model on multiple GPU can overcome the GPU memory bottleneck, but this is complicated process and resource expensive
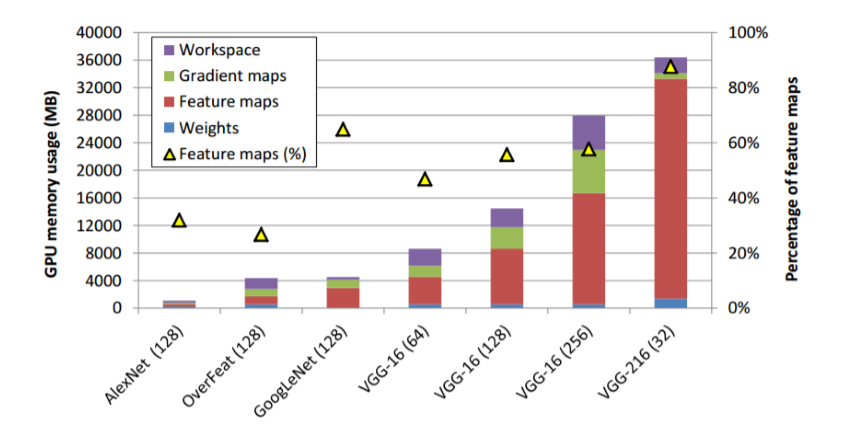
- Reduction of model Size: Model size could be reduced by reducing model parameters, feature maps, gradient maps
According to the observation of Minsoo Rhu et al. 2016. GPU memory is mostly occupied by four parts:
- Feature maps are intermediate representations in forward processing
- Model parameters (weights)
- Gradient maps are intermediate representations in backward processing
- Workspace is a buffer zone for CuDNN to temporarily store variables/data types. Buffer is freed after a function is returned during the processing.
However, feature maps are the most memory-consuming parts and it is directly proportional to the number of layers. Minsoo Rhu et al. suggested that one way to free the GPU memory usage during training is to use CPU memory as a temporary container [1].
Another way to train ML / DL models effectively is to follow the optimization strategy in:
- Forward and backward Propagation: vDNN optimises memory allocation by offloading and prefetching features maps to GPU memory to reuse in backward propagation. The memory can be freed up to be used for something else. One disadvantage is that if the network topology is non-linear, one tensor of feature maps may be utilised for several layers, making offloading impossible. In the backward process, gradient maps are not reused for later processing as compared to feature maps. Therefore, once weights are updated, they can be released.
- Memory management of CUDA Stream: A cuda stream, which manages memory allocation/release, offload, and prefetch, is a core part of vDNN. The standard cuda memory allocation and release APIs are synchronous. Synchronous APIs are inefficient because they occur frequently throughout the training process. The offloading and prefetching APIs, like the allocation/release procedures, must be asynchronous. This will allow vDNN to asynchronously start the computation of the current layer and prefetching of its previous layer at the same time.
The question arises how we can get the best performance given limited memory and avoid the RED-AI trend. The simple solution is to re-formalize the problem considering all above-mentioned constraints. It is also worth considering the trade-off between time and space as if we use more workspace (buffer zone) faster will be algorithm training with more GPU usage and vice versa. In order to acquire the best configuration, we must decide on two things for each layer; whether or not to offload/prefetch, and what algorithm to utilise for its forward/backward process.
REFERENCES:
[1] Rhu, M., Gimelshein, N., Clemons, J., Zulfiqar, A., & Keckler, S. W. (2016, October). vDNN: Virtualized deep neural networks for scalable, memory-efficient neural network design. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) (pp. 1-13). IEEE.