Text by: Chaudhary Muhammad Aqdus Ilyas, Department of Computer Science & Technology, University of Cambridge
In the past decade, the field of artificial intelligence (AI) has made significant strides in a wide range of capabilities, including object recognition, gamification, virtual reality (VR), speech recognition, and machine translation [1]. It is observed that the computational cost of state-of-the-art methods has increased 300,000x in recent years, learning from Alexnet in 2012 to Alphazeroin 2017 [2, 3]. This trend is marked as RED-AI, which stems from the shift of focus of the AI community to accuracy rather than efficiency. RED-AI tends to have larger carbon footprints and makes it difficult for academics, students and researchers to engage in deep learning research [4]. This trend is quite fast evident in NLP word-embedding methods where there is a strong focus on the AI community to achieve “state-of-the-art” results through the use of massive computational power (GPU usage) while ignoring the cost or efficiency.
However, there is a direct relationship between model performance and model complexity (number of parameters); that is for a linear gain in performance, an exponentially larger model is required. Similar trends follow with increasing the quantity of the training data and number of experiments [5, 6].
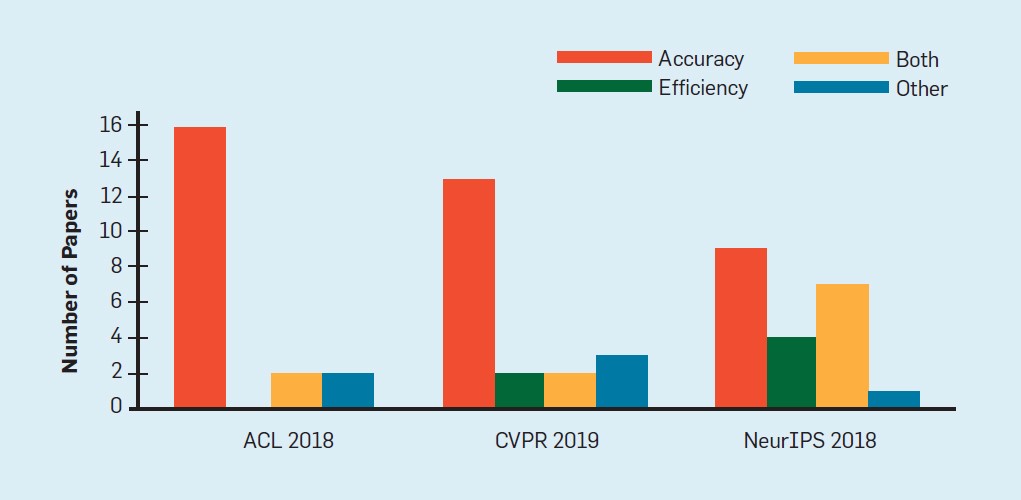
Figure 1: AI papers tend to target accuracy rather than efficiency. The figure shows the proportion of papers that target accuracy, efficiency, both or other from a random sample of 60 papers from top AI conferences. (Amodei et al. 2018)
To better understand the prevalence of RED-AI, Amodei et al. randomly selected the 60 papers from top AI conferences (CVPR, NeurIPS and ACL) and identified their contributions as:
- Accuracy improvement
- Efficiency improvement
- Both a) and b)
- Other
As demonstrated in Figure 1, in all conferences, a vast majority of the papers target accuracy (90% of ACL papers, 80% of NeurIPS papers, 75% of CVPR papers). In addition, only 10-20% of papers (ACL and CVPR) argue for new efficiency results. This highlights the focus of the AI community to concentrate on accuracy at the expense of speed or model size.
The most prominent factors that contribute towards the computational expensiveness of the models are:
- Size of the training dataset
- Number of hyperparameters that controls the number of times the model is trained during the model development
- Number of examples to be executed (during training or at inference time)
All of the above-mentioned factors contribute directly to the increase in the cost of machine learning models. Large models have a high cost of processing, which leads to large training costs. For instance, Google’s BERT-large contains approx 350 million parameters and was trained on 64 TPU chips for four days at an estimated cost of $7000 [3].
In the WorkingAge project, for training models to valence and arousal from facial data, we focussed on processing and analysing a large amount of lab-based video data, collected from four different sites namely, ITCL, BrainSigns (BS), Audeering (AUD) and the University of Cambridge (UCAM). This data comprised 45 subjects with more than 128 GB of data. To train the models using this data, with a specific protocol (Leave-on-site-out (LOSO)) and specific network (CNN-LSTM) on the 4 parallel GPU nodes, it took approximate 46 hours (11.5 *4 hours at each node). This model training is quite computational expensive to target accuracy metrics. Similarly, high cost is associated with further parameter tuning to achieve the required model accuracy. Despite the rising cost, larger datasets and higher parameters, RED-AI has pushed the boundaries of AI, however, there is still the possibility to limit the model size, dataset size and hyperparameters to make the model efficient. We will discuss this in detail in the next blog.
REFERENCES
[1] Zhang, D., Mishra, S., Brynjolfsson, E., Etchemendy, J., Ganguli, D., Grosz, B., … & Perrault, R. (2021). The ai index 2021 annual report. arXiv preprint arXiv:2103.06312.
[2] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
[3] Amodei, D., & Hernandez, D. (2018). AI and compute, 2018. URL https://openai. com/blog/ai-and-compute, 4.
[4] Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
[5] Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., Fathi, A., … & Murphy, K. (2017). Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7310-7311).
[6] Halevy, A., Norvig, P., & Pereira, F. (2009). The unreasonable effectiveness of data. IEEE intelligent systems, 24(2), 8-12.